最近はAIというとコード生成の性能が良くなった悪くなったとか、数学の能力が上がったとかそういう感じで、画像生成に関してあんま盛り上がりないよなと感じている。まあでも、ChatGPTで生成した画像をアイコンにしてる人とかは増えたよね。そういう意味では、流行りというよりむしろ一般に普及したという感じなのかも。
最近の画像生成のトレンドは自分ではあんまり追ってなかったのでgpt-image-2とかGemini Omniとかそれくらいしか見てなかったんだが、Animaというモデルが出たと風の噂で聞いたので久しぶりにローカル画像生成を触ってみた。
以下、Animaで生成された画像が含まれます。画像生成モデルによる生成物が苦手な方は閲覧をお控えください。
とりあえず動かしてみる
ComfyUIが楽そうなので今回はComfyUIを使う。ComfyUIを持っていない人はGitHubからポータブル版をダウンロードしてくるだけ。
Animaのモデルは、Huggingfaceのリポジトリからanima-base-v1.0.safetensors、qwen_3_06b_base.safetensors、qwen_image_vae.safetensorsをそれぞれダウンロードして指定されたディレクトリに置くだけ。以上
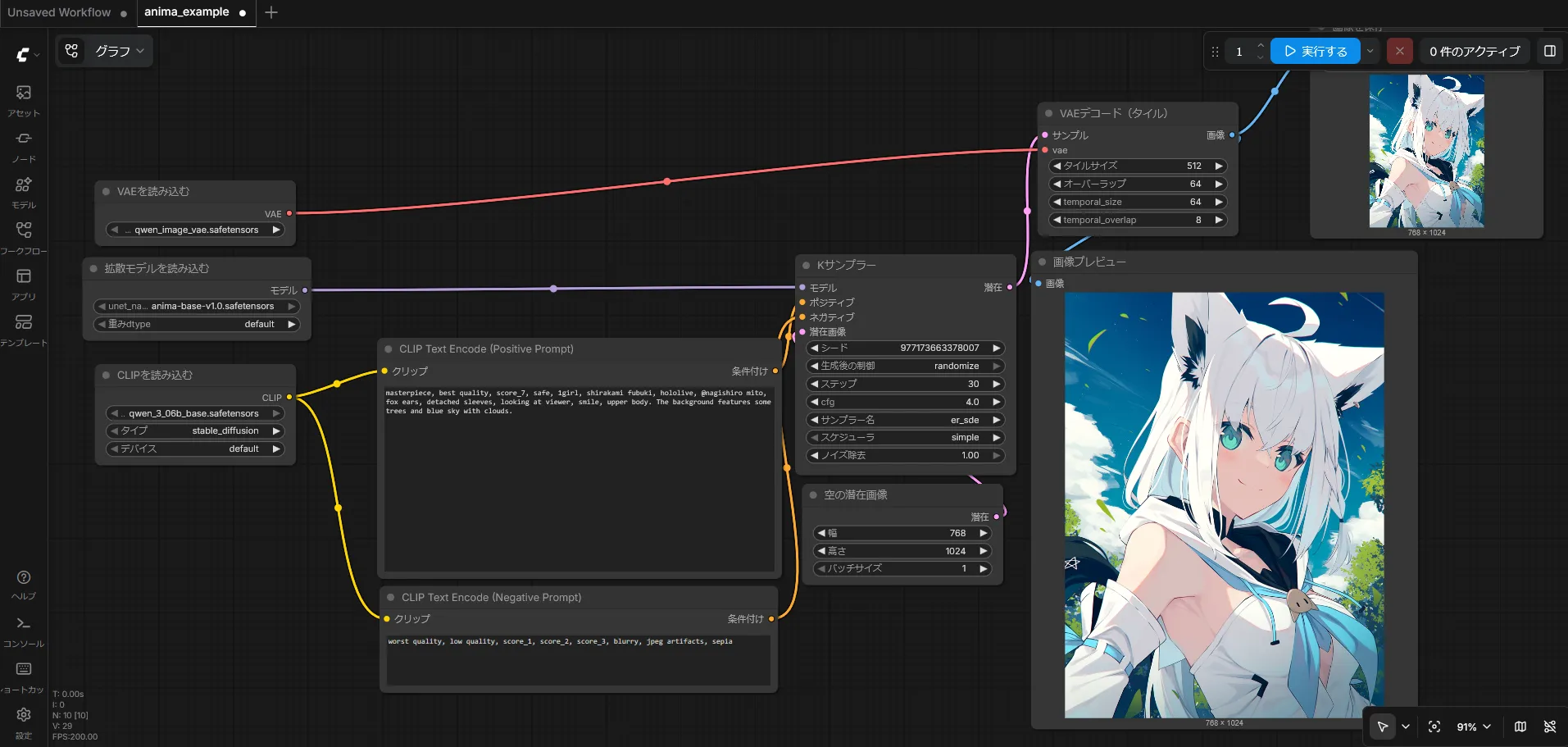 ComfyUIのワークフロー
ComfyUIのワークフロー
こんな感じで最低限のワークフローを組めば、そのまま生成できる。
自分はRTX 3070(VRAMが8GB)なんだけど、公式のワークフローをそのまま使うとVAE Decodeの部分で数分詰まるということが発生したので、TiledのVAE Decodeノードを使用している。VRAM消費は~6GBくらいな感じ。
※ ここに掲載している画像は圧縮されているため、ワークフローは埋め込まれてないので注意。
 Animaで生成された画像の例
Animaで生成された画像の例
 Animaで生成された画像の例2
Animaで生成された画像の例2
 Animaで生成された画像の例3
Animaで生成された画像の例3
 Animaで生成された画像の例4
Animaで生成された画像の例4
生成が遅い
AnimaのモデルのサイズはSDXLと同じくらいなのだが、AnimaはU-NetではなくDiffusion Transformer (DiT)というアーキテクチャを採用しており、この影響でそのままだと結構画像の生成に時間がかかる。
Animaのモデルカードの情報によれば生成時の設定として30から50ステップが推奨されているのだが、自分の環境だと1024x1024サイズの画像を生成しようとすると1itに1.5秒くらいかかった。ということは、1枚の画像を生成するのに50秒くらいかかってしまうということ。これは遅い。
これの対策として、公式からTurbo LoRAが公開されている。これを使うと、8-12ステップで画像を生成できる。速い。ただしその分プロンプトでの指示がちょっと難しくなる。
色々試してみる
Animaの特徴として、Danbooruタグも使えるし自然言語も使えるというのがある。タグだけでは複雑な内容の説明には限界があると以前から思っていたので、これは面白い。自然言語でうまく指定してやることで、プロンプトだけで複数キャラの書き分けができるらしい。
とりあえず色々やってみよう
 2人のキャラクターを生成する例
2人のキャラクターを生成する例
複雑な工夫はしておらず、プロンプトでキャラクターの特徴や位置を指定しただけ。
手がバグっているのは、まあそんなもんかという感じがする
ステップ数を上げたら多少は改善されたりするかも。この画像は35ステップで生成している。(Turbo LoRAを使用していない)
逆に手がバグってるのにそれ以外の部分は結構それらしく生成できるのがびっくり。
全体をパッと見た感じは、「良いイラストだなー」と思ってしまう。
こんだけ絵の上手いっぽさがあるのに、手とかの細部を見たら破綻してるってすごい不思議
 2人のキャラクターを生成する例2
2人のキャラクターを生成する例2
エロあるよ(笑)
AnimaはNSFWなコンテンツも普通に生成できる。ので、試してみた
 スナネコ
スナネコ
 裸の国王様
裸の国王様
あなたは18歳以上ですか?
露骨なのは載せると気まずいから自分でやってくれ!